LLM Component
Process the data accessed by this component according to the description of the prompt and structure it into the required format for use by subsequent components.
Scenarios
The LLM is a core component of the pipeline. It leverages the generation, summarization, extraction, classification, retrieval, and other processing capabilities of large language models to handle specific links within data synthesis and model evaluation pipelines according to given prompts.
Example Pipeline: Question Generation
The following figure illustrates a pipeline designed to generate questions based on a document:
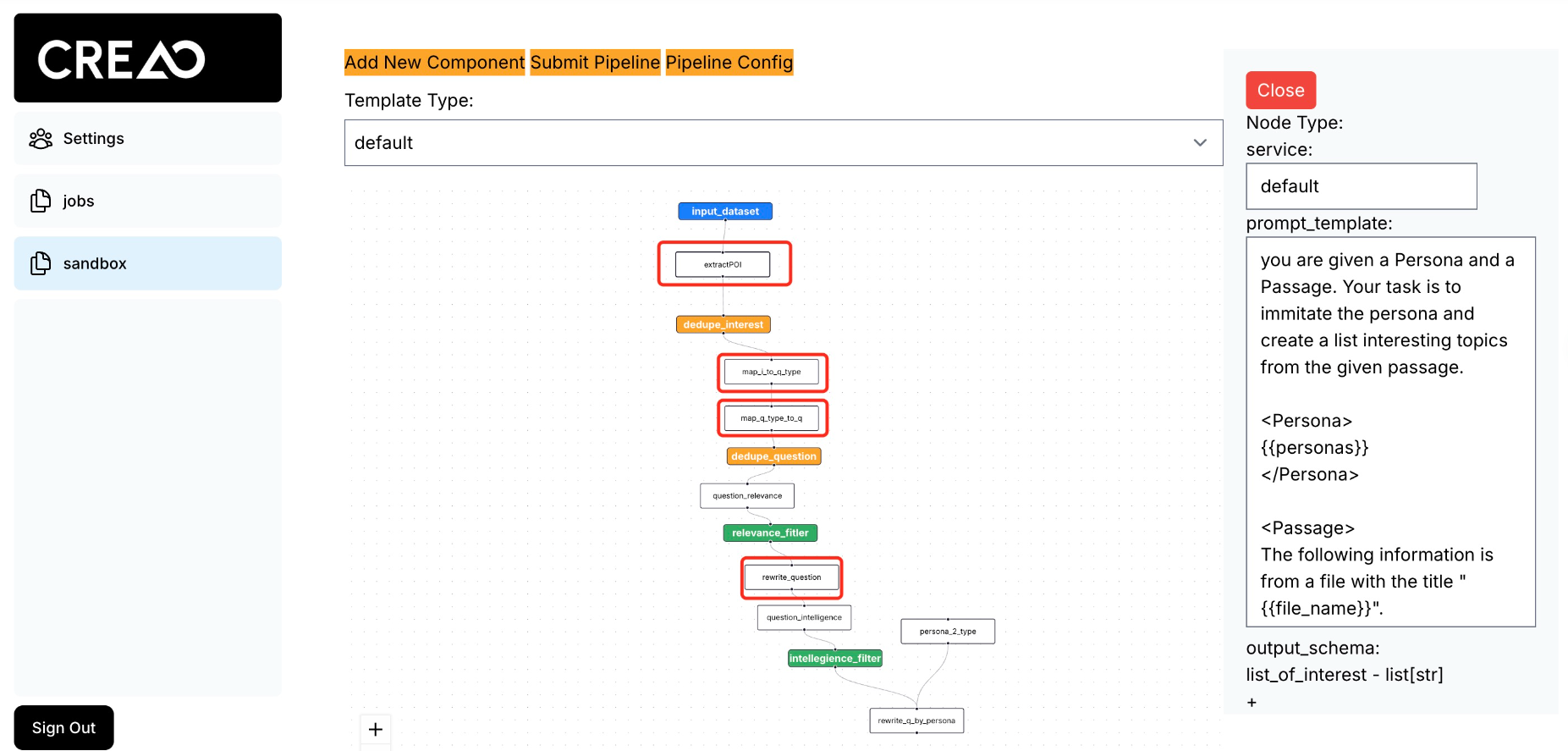
Configuring the Pipeline
-
Add an Input Component: Ensure you configure the correct address of the Hugging Face dataset. Once the pipeline is running, the dataset will be loaded into the pipeline.
-
LLM Component Capabilities:
- Generate Points of Interest: Extract key points from document chunks.
- Infer Question Types: Determine question types based on the identified points of interest.
- Generate Questions: Create questions using points of interest, context, and inferred question types.
- Rewrite Questions: Refine questions to enhance clarity and avoid overly basic phrasing.
Example: Generating Points of Interest
To generate points of interest from document chunks, use the following prompt format:
You are given a Persona and a Passage. Your task is to imitate the persona and
create a list of interesting topics from the given passage.
<Persona>
{{personas}}
</Persona>
<Passage>
The following information is from a file titled "{{file_name}}".
{{prompt}}
</Passage>
Answer Format:
Generate a JSON with the following field:
- "list_of_interest": [<fill with 1-5 word descriptions>]
Configuration
Configuration Steps
-
Write Prompt: Describe in detail the data that needs to be processed by the LLM, the logic of processing data, and the output format. The prompt should follow the syntax of the Jinja2 template engine. For more information on Jinja2 usage, visit: Jinja2 Documentation.
-
Set the Structured Output Data Format:
- Standard Output Modes: Two types of standard output modes are supported:
str: Choose this mode if you want to add fields to each piece of data based on the output of the previous component. This mode supports configuring multiple fields at once.list[str]: Choose this mode if you need to identify classifications or summarize characteristics based on the output of the previous component.
- Standard Output Modes: Two types of standard output modes are supported:
Component Input
The input is a list where each element is a dictionary. Each dictionary has the same fields and consistent data types. When editing the component prompt, you can reference these fields by inputting /.
Component Output
The output is a list generated by the LLM component. Each element in the list is a dictionary containing the standard output fields configured by the component.