Creao Pipeline
The Creao Pipeline is a framework that allows you to build and streamline the process of large-scale data generation. By connecting various components—each designed to perform a specific task—you can create a structured workflow that processes data efficiently and consistently.
What is a Pipeline?
A pipeline in the context of data processing is a series of steps or stages through which data is transformed, analyzed, or manipulated. Each stage in the pipeline is responsible for a specific part of the overall process, such as filtering data, generating outputs, or removing duplicates.
Pipeline Configuration
The pipeline configuration is accessible through the navigation bar on the right-hand side, where you can define key settings such as:
- hf_data_path: This specifies the input dataset for the entire pipeline. The pipeline will process each row of the dataset sequentially until all data is processed. After specifying the input dataset, click "Update Dataset" to refresh the pipeline and identify which columns are available for use.
- Add Variable Section: This section allows you to add both custom variables and dataset variables. The definitions and details for these variables can be accessed in the following section.
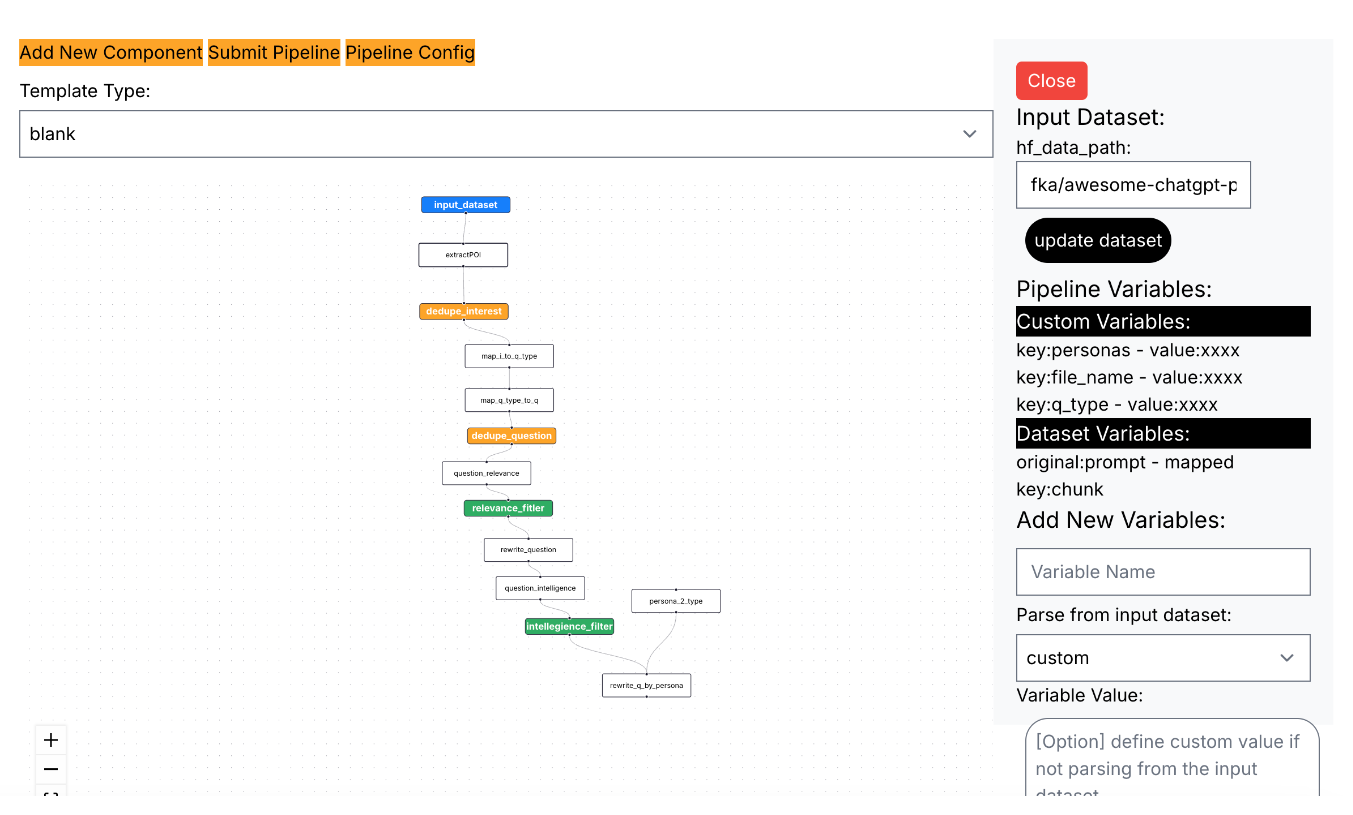
Components
Components are the building blocks of the Creao pipeline. Each component performs a specific function, such as data processing, filtering, or transformation. By connecting various components together, you can create complex pipelines tailored to your specific data needs.
To learn more about the available components and how to use them, refer to the following documentation:
Data & Variables
To effectively use the Creao pipeline, it's crucial to have a solid understanding of data and variables. Please refer to the following documentation to learn more: