Data & Variables
To effectively use the Creao pipeline, it's crucial to have a solid understanding of data and variables. In Creao, each component can interact with three types of data and variables:
Types of Data & Variables
1. Output from the First Preceding LLM Component
Components in the pipeline can access the output generated by the first preceding LLM (Large Language Model) component. If the component immediately before it is a dedupe or filter component, the system will trace back to the first LLM component to obtain the relevant output variables.
2. Custom Pipeline Variables
You can define your own global variables in the "Add New Variable" section. These variables, such as personas and file_name, are accessible to all components within the pipeline, allowing for customized and dynamic processing.
3. Dataset Variables
Each pipeline is associated with a single input dataset. After processing, this dataset is transformed into a List[Dict[str, str]] format, where each list item corresponds to an input record. You can define specific columns from this dataset as new variables in the pipeline. By selecting the option to parse from an input dataset column, these variables become accessible to all components in the pipeline.
This structure ensures that data flows smoothly through the pipeline, with components dynamically accessing the necessary variables and outputs to perform their designated tasks. Currently, we only support directly importing datasets from Hugging Face (as shown in the table below).
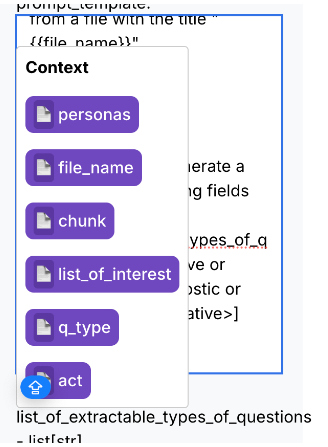
Convenient Variable Selection
We offer a convenient feature that allows users to easily select from available components while developing prompts. By simply typing '/', all the accessible variables will be displayed for quick selection, streamlining the process of building and customizing your pipeline.