Dedup Component
The Dedup Component is designed to identify and remove duplicate records in a dataset, ensuring data uniqueness and accuracy.
Scenarios
When the LLM component generates datasets through prompts, duplicates may arise. These duplicates can impact the accuracy of model evaluation and fine-tuning. The Dedup Component simplifies the process of detecting and removing such duplicates.
Example Pipeline
Consider the following pipeline for generating questions based on a document:
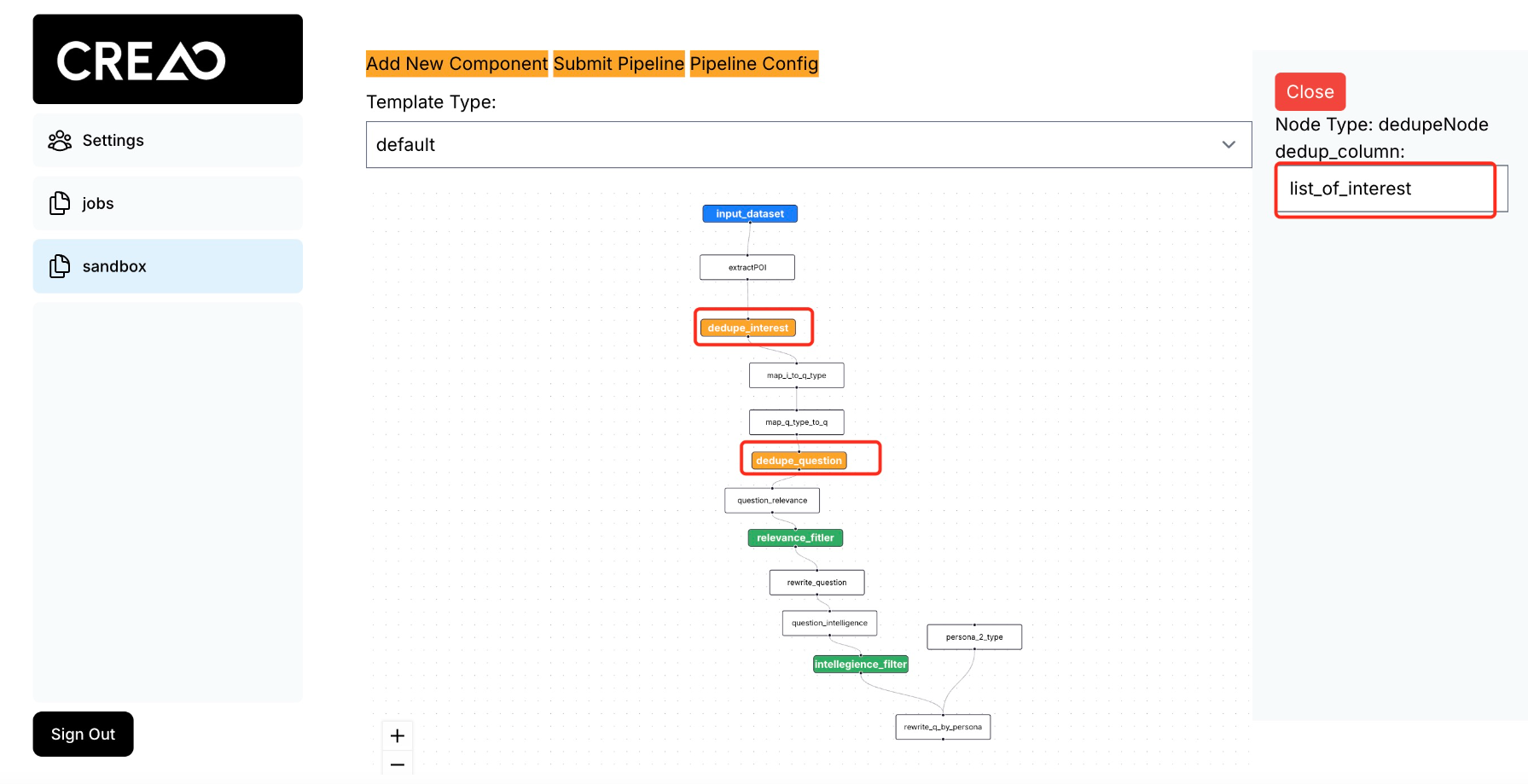
Capabilities
The Dedup Component can:
- Deduplicate Points of Interest: Remove duplicate entries from the list of points of interest.
- Deduplicate Generated Questions: Ensure uniqueness in generated questions.
For example, to deduplicate points of interest, the component configuration is as follows:

In this configuration, the component will find and remove duplicate entries in the list_of_interest field.
Configuration
Configuration Steps
- Configure the Deduplication Field: Specify the field by which the component will identify and remove duplicates. The component will automatically detect and delete duplicate data based on this field's value.
Component Input
- Type: List of dictionaries.
- Description: Each dictionary in the list has consistent fields.
Component Output
- Type: Processed list of dictionaries.
- Description: The output list is deduplicated based on the values of the configured field, ensuring no duplicate entries.