Data Component
The Data Component is used to load Hugging Face dataset into the pipeline, serving as the basis for generating synthetic data samples or preparing data for subsequent evaluation models/fine-tuning models.
Scenarios
For example, when it is necessary to generate questions that users may have based on a document or knowledge base. This component can be used to load the document or knowledge base into the pipeline. The following figure is a pipeline for generating questions that users may ask based on a document:
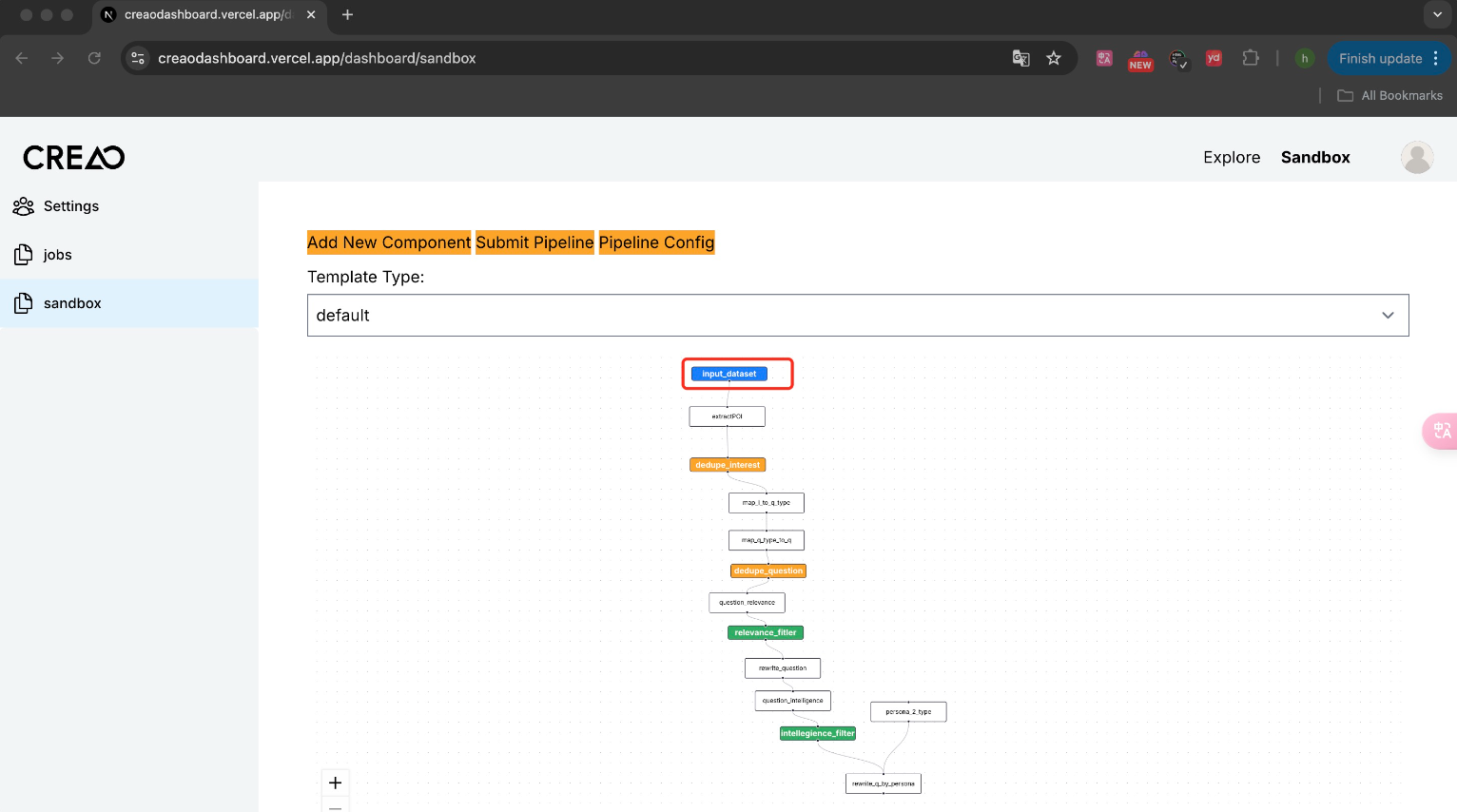
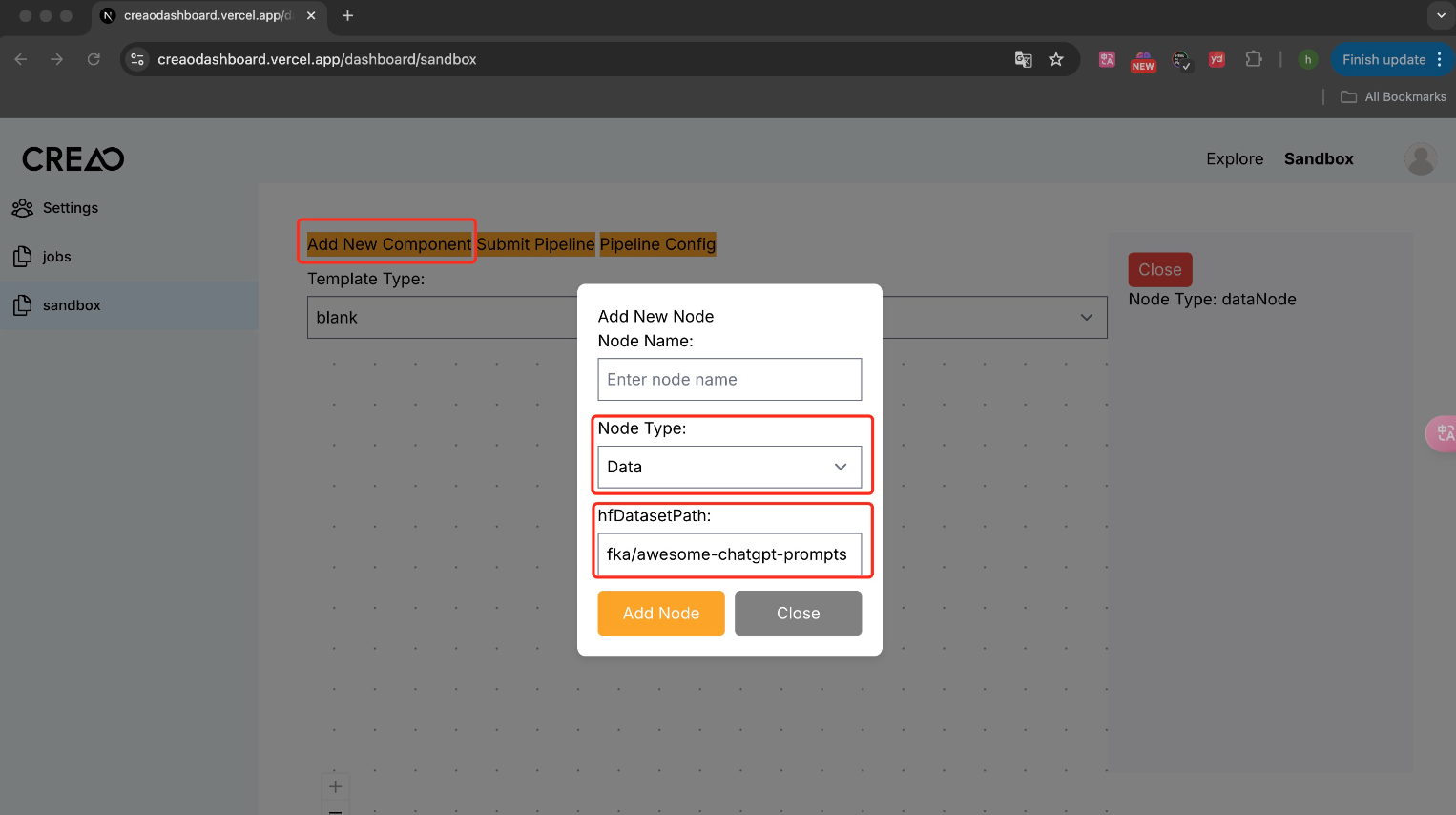
When adding an input component, configure the correct address of the Hugging Face dataset. Then the pipeline is running, this dataset can be loaded into the pipeline.
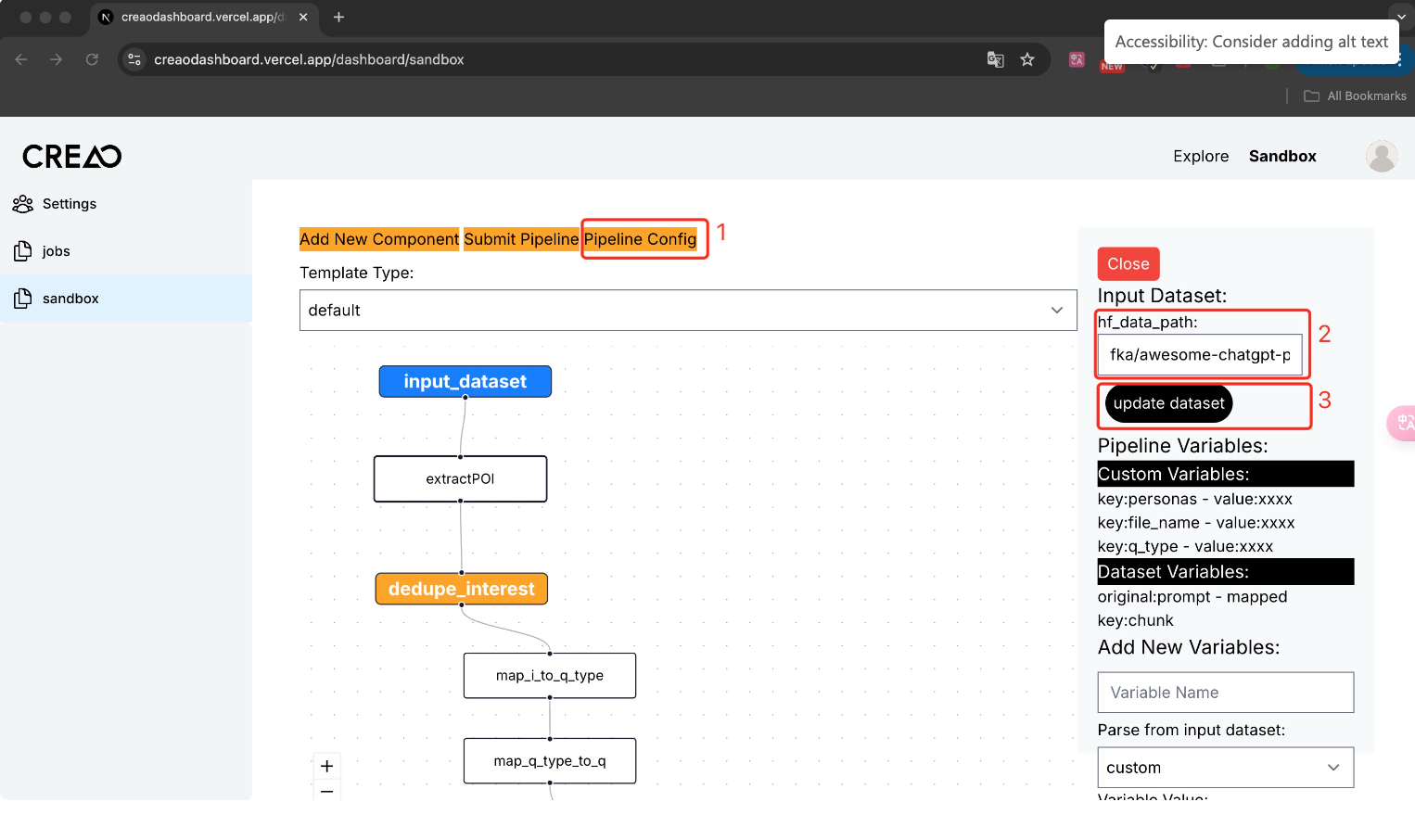
When you need to modify the dataset, you can modify it in the pipeline configuration.
Configuration
Configuration Steps
- When creating a component, fill in the link of the dataset. It should be noted that currently only loading Hugging Face datasets is supported, and a pipeline can only be configured with one dataset.